3. Objectif stratégique 3 : Atténuer les effets de la sécheresse, s’y adapter et les gérer, afin de renforcer la résilience des populations et des écosystèmes vulnérables
3.1 Objectif stratégique 3-1 – Évolution de la proportion de terres frappées par la sécheresse au regard de la superficie totale
3.1.1. Introduction
La Convention des Nations unies sur la lutte contre la désertification (UNCCD) définit la sécheresse comme un phénomène naturel qui se produit lorsque les précipitations sont nettement inférieures aux niveaux normaux enregistrés, provoquant de graves déséquilibres hydrologiques qui ont des effets néfastes sur les systèmes de production des ressources terrestres[1].
L’indicateur SO 3-1 décrit spécifiquement l’état (c’est-à-dire l’occurrence ou l’absence de sécheresse et sa gravité, le cas échéant) des risques de sécheresse météorologique sur une base annuelle dans un pays.
Il existe plusieurs indices de sécheresse qui peuvent être utilisés pour estimer le risque de sécheresse au niveau national. La méthodologie de l’UNCCD pour estimer l’indicateur SO 3-1 recommande d’utiliser un indice de sécheresse spécifique accepté au niveau mondial, connu sous le nom d’indice de précipitations normalisé (SPI), pour caractériser le risque de sécheresse météorologique. Toutefois, les parties peuvent utiliser d’autres indices s’ils sont déjà utilisés au niveau national, par exemple l’indice standardisé d’évapotranspiration des précipitations (SPEI). Pour les autres indices actuellement utilisés, les Parties peuvent avoir besoin de s’assurer de la cohérence statistique avec les classes d’intensité de la sécheresse de l’IPS décrites dans le tableau 19[2].
L’objectif global est que les parties évaluent le risque de sécheresse et identifient les zones touchées par la sécheresse afin de hiérarchiser les efforts d’atténuation en liaison avec les évaluations de l’exposition à la sécheresse (OS 3-2) et de la vulnérabilité (OS 3-3). Les rapports nationaux sont facilités par la fourniture de données par défaut.
3.1.2. Conditions préalables à la présentation de rapports
Une lecture approfondie du chapitre 1 du Good Practice Guidance for National Reporting on UNCCD Strategic Objective 3: To mitigate, adapt to, and manage the effects of drought in order to enhance resilience of vulnerable populations and ecosystems qui détaille la méthodologie employée pour estimer les risques de sécheresse et les variations au fil du temps ;
Données conformes aux spécifications énumérées à la figure 5 et au tableau 18.
Une réserve de spécialistes nationaux officiellement nommés par les autorités nationales pour vérifier la cohérence des résultats du cycle de présentation des rapports au regard de la situation sur le terrain, ou pour élaborer et mettre en œuvre une méthodologie personnalisée pour estimer l’indicateur de l’objectif stratégique 3-1 si les données nationales sont privilégiées par rapport aux données par défaut. Parmi les principales institutions figurent le service météorologique et hydrologique national (SMHN) du pays, le ministère de l’Environnement, le ministère de l’Agriculture, un centre de télédétection et le bureau national de la statistique, ainsi que des universités et des centres de recherche compétents dans le domaine.
3.1.3. Cycle de présentation des rapports et procédure étape par étape
La procédure étape par étape de présentation des rapports est décrite ci-après. Si l’on utilise les données par défaut, les étapes 2 à 5 ne sont pas nécessaires.
Étape 1 : Sélection de l’indice de sécheresse ou de l’ensemble de données sur les précipitations
L’UNCCD fournit des données par défaut du Global Multi-Index Drought (GMID) Product, un ensemble quadrillé d’indices de sécheresse qui comprend le SPI et le SPEI calculés à l’aide de données de précipitations dérivées de la combinaison de pluviomètres, d’observations par satellite et de données de réanalyse. Voir l’encadré 5 ci-dessous pour une vue d’ensemble de ce produit.
Bien que l’indice SPI reste l’indice recommandé pour estimer l’indicateur SO 3-1, les Parties devraient déterminer si l’indice SPEI est plus approprié à leurs circonstances spécifiques, en particulier dans les zones arides et semi-arides où les précipitations sont irrégulières et les quantités cumulées sont faibles. Comme l’IPS tient compte à la fois des précipitations et de la température de l’air, il peut fournir une mesure plus précise de la disponibilité de l’eau dans ces zones, où les pertes par évapotranspiration peuvent être importantes. Une discussion plus détaillée sur les cas où un indice peut être préféré à l’autre se trouve dans la section 1.5 du [Guide des bonnes pratiques pour l’établissement des rapports nationaux sur l’objectif stratégique 3 de la CNULD] (https://www.unccd.int/publications/good-practice-guidance-national-reporting-unccd-strategic-objective-3-mitigate-adapt).
Si les pays parties disposent déjà d’un indice de sécheresse national tel que le SPI ou le SPEI, ils peuvent l’utiliser de préférence aux données par défaut de la CNULD. Par ailleurs, s’ils souhaitent calculer eux-mêmes l’indice SPI, ils ont la possibilité d’utiliser un jeu de données alternatif fourni par Trends.Earth ou d’utiliser les données de précipitations du pays.
Le jeu de données alternatif disponible via Trends.Earth est le Climate Hazards Group InfraRed Precipitation with Stations (CHIRPS), qui produit des estimations de précipitations à haute résolution basées sur des observations par satellite et des données de stations jaugées. Si la résolution spatiale légèrement supérieure de CHIRPS est un avantage pour le calcul de l’indice SPI, elle présente l’inconvénient de ne pas avoir une couverture mondiale et de ne s’étendre que de 50°S à 50°N. Par conséquent, les parties dont les frontières nationales se situent en dehors de cette fourchette ne pourront pas utiliser le jeu de données CHIRPS. En revanche, le GMID a une couverture mondiale. Alors que le GMID comprend à la fois le SPI et le SPEI, pour CHIRPS, seul le SPI sera disponible dans Trends.Earth.
L’arbre de décision de la figure 5 peut aider les Parties à décider de l’ensemble de données et de l’approche les plus appropriés pour soutenir la notification de leur situation nationale.
Figure 5.** Arbre de décision pour aider les Parties à choisir la meilleure source de données sur les précipitations ou l’indice de sécheresse pour dériver l’indicateur SO 3-1_.
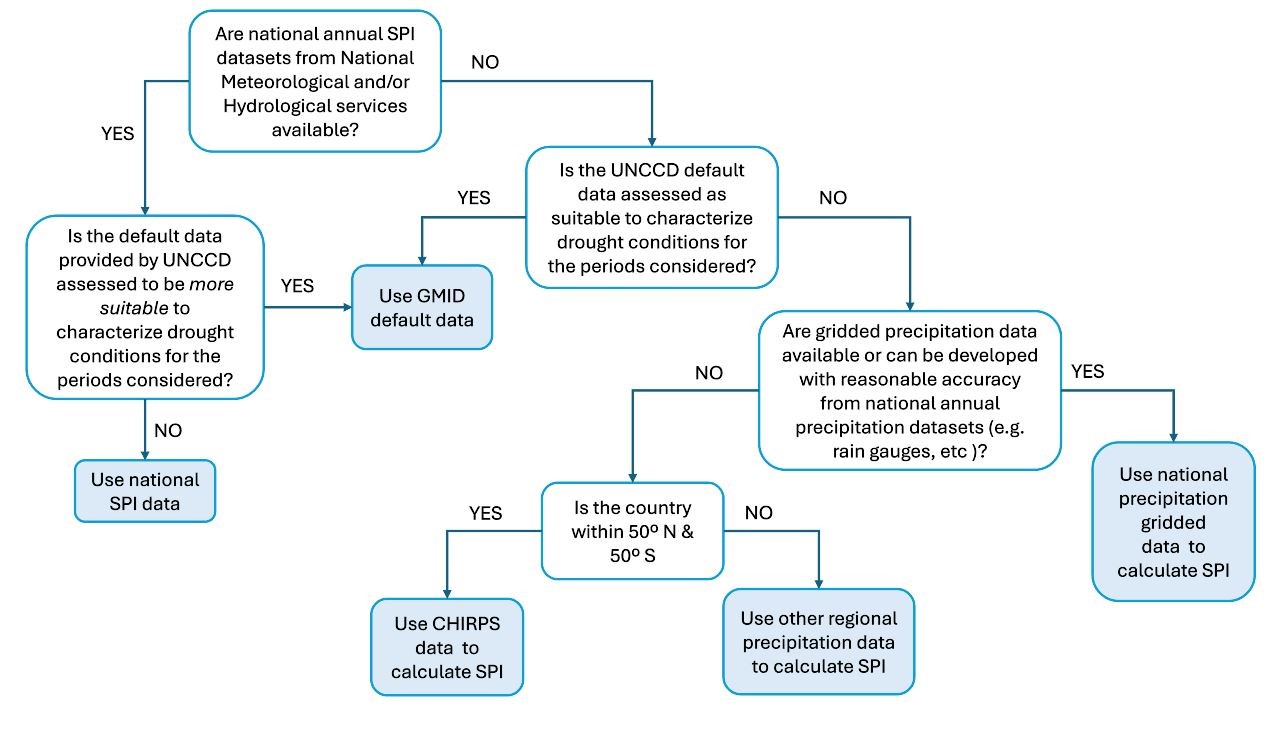
GMID : Global Multi-Index Drought,
(indice global de sécheresse) SPI : Standardized Precipitation Index,
CHIRPS : Climate Hazards Group InfraRed Precipitation with Stations (Précipitations infrarouges avec stations)
Ce processus de prise de décision devrait aider les Parties à identifier les données qui répondent aux spécifications résumées dans le tableau 18.
Élément |
Spécifications |
|
|---|---|---|
Données par défaut |
Données nationales |
|
Données d’entrée Données nécessaires pour produire des estimations de l’aléa sécheresse basées sur les calculs de l’indice standardisé des précipitations (SPI) décrits à l’étape 2 |
Produits mensuels de l’indice de sécheresse Global Multi-Index Drought (GMID), 1980-2023. |
Produits maillés des précipitations totales mensuelles dérivées des réseaux nationaux de jaugeage. Afin de calculer la période de référence alignée sur l’OMM, le jeu de données devrait idéalement avoir un enregistrement continu d’au moins 30 ans, couvrant la période 1981-2010. Pour les pays situés entre 50°S et 50°N : Les produits mensuels de précipitations du Climate Hazards Group InfraRed Precipitation with Stations (CHIRPS), 1981-présent, sont accessibles dans Trends.Earth*. Des périodes d’accumulation alternatives à SPI-12 sont également possibles dans Trends.Earth lorsque vous utilisez CHIRPS, par exemple SPI-9, SPI-24 et SPI-48. |
Données de sortie Produits maillés intermédiaires et finaux résultant de l’analyse décrite aux étapes 2 à 4 |
Grilles SPI-12 de décembre classées en quatre classes d’intensité de sécheresse SPI sur une base annuelle*. Superficie totale des terres pour chaque catégorie d’intensité de sécheresse ainsi que proportion de la superficie totale frappée par la sécheresse. Résumé spatial en grille par périodes de quatre ans. |
Grilles SPI-12 annuelles de décembre classées en quatre classes d’intensité de sécheresse SPI sur une base annuelle*. Superficie totale des terres pour chaque catégorie d’intensité de sécheresse ainsi que proportion de la superficie totale frappée par la sécheresse. Résumé spatial en grille par périodes de quatre ans. |
Classification |
Quatre catégories d’intensité de sécheresse de l’IPN conformément au tableau 19. |
Quatre catégories d’intensité de sécheresse de l’IPN conformément au tableau 19. |
Résolution spatiale |
GMID : 0,1° x 0,1° (~11,1 km) |
CHIRPS : 0,05° x 0,05° (~5,55 km) ou autrement évaluée par les autorités nationales en fonction des données disponibles. |
Qualité |
Précisée dans les métadonnées des ensembles de données. |
Les données doivent être continues dans la mesure du possible ; lorsque l’exhaustivité des données est inférieure à 85 %, les parties peuvent envisager de combler les lacunes en matière de données conformément aux orientations de l’Organisation météorologique mondiale (OMM, 2018). |
Métadonnées |
Des métadonnées sont fournies avec les données par défaut. |
Les métadonnées minimales exigées pour chaque champ obligatoire sont énumérées à l’annexe II. |
* Comme indiqué à l’étape 3, les valeurs de décembre de l’IPN sur 12 mois représentent les déficits (ou les excédents) de précipitations sur une année du calendrier grégorien (janvier-décembre).
Encadré 5. L’ensemble de données du Global Multi-Index Drought (GMID)
Ce jeu de données comprend l’indice standardisé des précipitations (SPI) et l’indice standardisé d’évapotranspiration des précipitations (SPEI) sur des échelles temporelles de 1 à 12 mois à haute résolution spatiale, couvrant la période 1980-2023 à l’échelle mondiale. Le jeu de données offre une couverture spatiale à travers les longitudes mondiales de -180° à 180° et les latitudes de 90° à -90°. Les données sont fournies en coordonnées géographiques (latitude/longitude) basées sur le système de référence WGS 84 (World Geodetic System 1984), à une résolution de 0,1°.
L’IPS et l’IPS ont été calculés sur la base de la distribution de probabilité la plus largement utilisée et recommandée pour leur calcul à différentes échelles de temps. Ainsi, l’IPS a été calculé en adoptant une distribution Gamma, tandis que l’IPS a été calculé en adoptant une distribution log-logistique. L’ensemble de données a été généré à l’aide de différents ensembles de données météorologiques d’entrée, notamment : les données de précipitations provenant du Multi-Source Weighted-Ensemble Precipitation (MSWEP) v2.8 (https://www.gloh2o.org/mswep/), et les données d’évapotranspiration potentielle dérivées du Global Land Evaporation Amsterdam Model (GLEAM) v4.2a (https://www.gleam.eu). Les données ont été téléchargées à des pas de temps quotidiens, puis agrégées mensuellement, et enfin résumées à différentes périodes d’accumulation pour obtenir les indices à des échelles de temps de 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 et 12 mois.
L’ensemble des données du GMID est disponible à l’adresse suivante : https://eidc.ac.uk/
Étape 2 : calculer l’IPN
Les séries temporelles mensuelles de l’indice SPI sont basées sur les données de précipitations maillées sélectionnées et calculées à l’aide de la méthode SPI-12, qui fournit un résumé annuel des déficits de précipitations pour chaque mois à l’aide d’une méthode d’accumulation sur 12 mois. Par exemple, l’accumulation des précipitations sur 12 mois pour décembre 2019 est le total des précipitations mensuelles de janvier 2019 à décembre 2019.
Il est important de veiller à ce que, pour chaque année de référence, les données sur les précipitations soient normalisées par rapport à la même “période de référence” ou période normale standard climatologique. Cela permet de garantir que les données sont comparables d’une année à l’autre, dans le temps et dans l’espace. Afin de normaliser les distributions de données d’accumulation de précipitations sur 12 mois, la période normale climatologique standard de l’OMM (1981-2010) est utilisée comme période de référence. La méthode de normalisation est basée sur une fonction de distribution de probabilité Gamma ajustée aux accumulations de précipitations sur 12 mois dans cette période de référence. Une fois calculés, ces paramètres de distribution de probabilité sont ensuite appliqués à toute série temporelle d’accumulations mensuelles de précipitations sur 12 mois pour produire la série temporelle SPI-12 mensuelle normalisée pour chaque cellule de la grille pour l’ensemble de la période pour laquelle des données sont disponibles. Toutefois, si les parties décident de modifier la période de référence de la normale climatique standard, il faut alors recalculer l’IPS pour toutes les périodes. Il est donc recommandé que la période de référence utilisée pour calculer l’IPS soit clairement indiquée dans les rapports nationaux de l’indicateur SO 3-1 à la CNULD.
Les données SPI et SPEI par défaut sont disponibles dans Trends.Earth aux fins de la surveillance du SO3. Cependant, il existe plusieurs outils en libre accès qui peuvent être utilisés pour calculer l’indice SPI, dont une sélection est répertoriée dans le tableau 3 du [Guide des bonnes pratiques pour les rapports nationaux sur l’objectif stratégique 3 de la CNULD] (https://www.unccd.int/publications/good-practice-guidance-national-reporting-unccd-strategic-objective-3-mitigate-adapt).
Étape 3 : identifier la catégorie d’intensité de sécheresse de chaque maille d’après la valeur calculée de l’IPN
Note
Domaines connexes sur la plateforme du système PRAIS 4 : tableau SO3-1.T1
Pour évaluer la série temporelle SPI sur une base annuelle, il convient d’extraire les valeurs SPI-12 de décembre pour chaque année. Les valeurs SPI-12 de décembre représentent les déficits (ou les excès) de précipitations sur l’année civile grégorienne (janvier-décembre).
Pour chacune des grilles SPI-12 de décembre, il convient de compter le nombre de cellules appartenant à chacune des classes d’intensité de la sécheresse SPI énumérées dans le tableau 19. Notez que toute cellule avec une valeur > 0 représente une zone sans sécheresse.
Valeurs de l’IPN |
Catégorie d’intensité de sécheresse |
|---|---|
De 0 à -0,99 |
Légère sécheresse |
De -1,0 à -1,49 |
Sécheresse modérée |
De -1,5 à -1,99 |
Grande sécheresse |
Inférieures ou égales à -2 |
Sécheresse extrême |
La superficie totale relevant de chaque catégorie d’intensité de sécheresse doit être calculée en deux temps :
Projetez la grille des classes d’intensité de la sécheresse dans une projection d’aire égale appropriée (par exemple, Mollweide) pour obtenir la superficie des cellules en km2.
Combinez la superficie de toutes les cellules dans une classe de sécheresse donnée pour obtenir la superficie totale dans chaque classe d’intensité de la sécheresse.
Étape 4 : Calculer la proportion de terres touchées par la sécheresse sans ventilation par classe
Note
Domaines connexes sur la plateforme du système PRAIS 4 : tableau SO3-1.T2
La proportion de terres touchées par la sécheresse, quelle que soit la classe d’intensité, est calculée pour chaque année de référence en pourcentage de la superficie totale des terres.
Pour chacune des grilles annuelles de l’indice SPI-12, le nombre total de cellules appartenant à l’une des classes d’intensité de la sécheresse de l’indice SPI est compté (cellCount). Ensuite, pour chaque année de déclaration, le pourcentage de la superficie totale des terres touchées par la sécheresse est calculé. La formule est la suivante :
\(P_{j} = \frac{compte_de_cellules_{j}}{\text{nombre_total_de_cellules}} \n- fois 100\)
Où :
“Pj” est la proportion de terres touchées par la sécheresse au cours de l’année de déclaration (j).
“cellCountj” est le nombre total de pixels touchés par la sécheresse au cours de l’année de déclaration (j).
« Total number of cells » désigne toutes les mailles situées au sein de la superficie terrestre du pays partie.
La superficie totale soumise à la sécheresse chaque année est calculée en multipliant cellCount par la superficie des cellules (une valeur constante, puisque la grille des classes d’intensité de la sécheresse a été précédemment convertie en une projection à superficie égale).
Étape 5 : Créer des cartes d’intensité de la sécheresse pour des périodes de quatre ans
En plus des rapports tabulaires décrits ci-dessus, l’indicateur SO 3-1 doit également être résumé dans l’espace pour cartographier les conditions de sécheresse les plus intenses qui se sont produites sur des périodes de quatre ans. Les périodes de quatre ans sont choisies pour réduire la charge de travail et la quantité de données qui seraient associées à un rapport annuel d’informations spatiales.
Pour résumer ces périodes dans l’espace, pour chaque cellule de la grille, la classe d’intensité de sécheresse la plus élevée dans cette cellule doit être identifiée au cours des périodes de quatre ans. Par exemple, si une cellule de la grille présente les valeurs (légère, légère, modérée, légère) pour une période de quatre ans donnée, la cellule doit contenir la valeur “modérée” pour cette période de quatre ans.
L’intensité de la sécheresse la plus élevée pour les périodes de quatre ans devrait être cartographiée à l’aide des données SPI-12 maillées par intervalles de quatre ans (2000-2003, 2004-2007, 2008-2011, 2012-2015, 2016-2019 et 2020-2023). Si les pays parties ont des lacunes (c’est-à-dire des années manquantes) dans leurs ensembles de données, ils doivent les résumer sur les périodes les plus appropriées afin de les aligner le plus possible sur les périodes quadriennales susmentionnées. Par exemple, si une partie de l’ensemble de données est représentée par 2004, 2007, 2008, 2009, 2011, les périodes de synthèse les plus appropriées seraient (2004, 2007) et (2008, 2009, 2011).
Étape 6 : vérifier les résultats
Les parties doivent être conscientes des limites liées à l’utilisation de l’IPS comme indicateur unique de sécheresse et examiner de manière critique les données par défaut par rapport aux données des pluviomètres nationaux et d’autres sources météorologiques avant de soumettre leurs rapports nationaux.
Étape 7 : Sauvegarder le formulaire et le mettre à disposition pour examen
Les changements observés et leur interprétation peuvent être décrits dans les champs de commentaires associés aux tableaux de rapport de la plateforme PRAIS 4.
Les cartes d’intensité de la sécheresse par défaut ou les cartes générées dans Trends.Earth à l’aide de données nationales représentant les conditions de sécheresse les plus intenses pour des périodes de quatre ans sont mises à disposition dans la plateforme PRAIS 4. Plus précisément, les cartes suivantes seront disponibles :
Conditions de sécheresse les plus intenses en 2000-2003
Conditions de sécheresse les plus intenses en 2004-2007
Conditions de sécheresse les plus intenses en 2008-2011
Conditions de sécheresse les plus intenses en 2012-2015
Conditions de sécheresse les plus intenses en 2016-2019
Conditions de sécheresse les plus intenses en 2020-2023
Les Parties doivent noter que les cartes quadriennales par défaut de l’intensité de la sécheresse sont basées sur les mêmes données par défaut que celles rapportées dans SO3-1.T1. Cependant, comme expliqué à l’étape 5, si une Partie rapporte des données nationales et qu’il manque des années, les cartes récapitulatives peuvent être produites en utilisant les données disponibles qui s’alignent le mieux avec les périodes quadriennales ci-dessus. Les parties sont également encouragées à soumettre des commentaires, en utilisant le champ “Commentaires généraux”, sur la méthodologie, les sources de données, l’exactitude des données et les lacunes dans les données dans le cas où les estimations sont dérivées des données nationales. Il serait également utile de rendre compte des cas et problèmes particuliers, en décrivant les situations dans lesquelles les valeurs de l’IPS pourraient être moins fiables et en justifiant l’adoption d’une méthodologie différente.
Une fois que le formulaire a été complété et vérifié par les Parties, il doit être marqué comme “En cours de révision” et sauvegardé. Une fois que l’UNCCD a terminé son examen et que tous les commentaires ont été résolus, le formulaire peut être marqué comme “Finalisé” et sauvegardé.
3.1.4. Dépendances
Les données sur les risques de sécheresse s’appuient sur la superficie totale des terres indiquée dans le tableau CP-1.T1 pour calculer la proportion de la superficie totale des terres soumise à la sécheresse. Les résultats de l’indicateur SO 3-1 sont également utilisés pour calculer l’indicateur SO 3-2.
3.1.5. Difficultés
Disponibilité et qualité des données
Les données sur les précipitations disponibles au niveau international pourraient ne pas être suffisamment précises pour estimer l’intensité du risque de sécheresse au niveau national. Il est recommandé d’utiliser les données nationales, car l’on part du principe qu’elles sont plus précises et plus fiables. Cependant, il se pourrait que les données nationales sur les précipitations ne soient pas facilement disponibles au format numérique et/ou que les séries chronologiques ne soient pas complètes.
Limites des estimations fondées sur l’IPN
Bien que l’IPS soit recommandé comme un indice de sécheresse bien établi, flexible et robuste pour quantifier le risque de sécheresse à l’échelle mondiale, il ne quantifie que les déficits météorologiques, puisqu’il est uniquement basé sur les précipitations, et d’autres types de sécheresse (par exemple, hydrologique, agricole) peuvent ne pas être bien pris en compte. De plus, dans les régions où la proportion de mois sans précipitations est très faible et/ou élevée, les valeurs de l’IPS doivent être utilisées et interprétées avec précaution ; l’application de l’IPSPE pourrait être plus appropriée dans ces régions. Conscient de cette limitation, l’expert national peut mettre en évidence les domaines dans lesquels les estimations basées sur l’IPS risquent de ne pas produire des résultats suffisamment précis et peut baser les estimations sur des indices alternatifs. Une discussion sur les limites de l’IPS peut être trouvée dans la section 1.5 du [“Guide des bonnes pratiques pour les rapports nationaux sur l’objectif stratégique 3 de la CNULD”] (https://www.unccd.int/publications/good-practice-guidance-national-reporting-unccd-strategic-objective-3-mitigate-adapt).
Les zones hyper arides sont incluses dans les données SPI fournies par défaut. Cependant, les valeurs de l’indice sur ces zones doivent être considérées avec précaution étant donné les limites du calcul de l’indice de sécheresse sur ces zones. Ces limitations peuvent entraîner une surestimation ou une sous-estimation des événements de sécheresse dans les zones hyper arides.
En raison de la variabilité naturelle du climat, tout changement ou tendance observé dans la proportion de terres touchées par la sécheresse au cours des périodes couvertes par le rapport doit être interprété avec prudence. Les anomalies et les incertitudes dans les estimations doivent être décrites dans le champ “Commentaires pour le tableau ci-dessus”.
L’échelle de temps adoptée et mise à disposition par les données par défaut du GMID, basée sur un cycle de 12 mois, pourrait ne pas toujours convenir à la caractérisation des impacts de la sécheresse dans certains environnements. Si les parties utilisent leurs propres données, elles devraient déterminer si d’autres périodes d’agrégation, par exemple 24 mois, pourraient être plus appropriées.
3.1.6. Résumé (principales étapes)
Les principales étapes à suivre pour présenter des rapports sur les valeurs d’intensité du risque de sécheresse sont les suivantes :
Sélectionnez l’indice de sécheresse ou le jeu de données sur les précipitations : Les Parties peuvent décider d’utiliser les données d’indice de sécheresse par défaut ou d’autres sources nationales, à condition qu’elles soient conformes aux spécifications des données énumérées dans le tableau 18. Si les Parties décident d’utiliser une autre source de données sur les précipitations, elles doivent suivre les actions 2 à 5 ci-dessous :
Calculer l’IPS : l’IPS doit être calculé pour tous les mois de la série chronologique complète disponible ; toutefois, les parties peuvent choisir d’autres indices (par exemple, l’IPS) mieux adaptés à leurs conditions environnementales locales.
Identifier la classe d’intensité de la sécheresse de chaque cellule de la grille : sur la base du calcul de l’indice SPI (ou d’un autre indice de sécheresse), le nombre de cellules appartenant à chacune des classes d’intensité de la sécheresse doit être compté et converti en surfaces en projetant les grilles des classes d’intensité de la sécheresse dans une projection de surface égale appropriée, et en calculant la surface totale de chaque classe d’intensité de la sécheresse en km2. Les données sont ensuite reportées dans le tableau SO3-1.T1.
Calcul de la proportion de terres soumises à la sécheresse : la proportion de terres dans chaque classe d’intensité de la sécheresse et la proportion globale de terres soumises à des conditions de sécheresse sur la superficie totale des terres sont calculées pour chaque année de déclaration et indiquées dans les tableaux SO3-1.T1 et SO3-1.T2.
Créer un ensemble de cartes de l’intensité de la sécheresse : les données pour l’ensemble de la série chronologique de 2000 à 2023 devraient être résumées spatialement en utilisant les données SPI-12 maillées, de préférence par intervalles de quatre ans (2000-2003, 2004-2007, 2008-2011, 2012-2015, 2016-2019 et 2020-2023) pour cartographier les conditions de sécheresse les plus intenses au cours de chaque période.
Vérifier les résultats : conscientes des limites liées à l’utilisation de l’indice SPI ou d’autres indices de sécheresse pour estimer l’intensité de la sécheresse, les parties devraient vérifier la pertinence d’un tel indice pour décrire l’occurrence et l’intensité de la sécheresse dans leur pays avant de soumettre officiellement des estimations pour l’établissement de rapports au titre de la CCD.
Sauvegardez le formulaire et mettez-le à disposition pour examen : Une fois vérifiées par les parties, les données et le texte justificatif doivent être marqués comme “en cours d’examen” et sauvegardés, ce qui les rend disponibles pour examen par la CNULD.
3.1.7. Ressources supplémentaires
OMM, 2018, Guide des pratiques climatologiques, deuxième édition. Genève, Suisse. (https://library.wmo.int/viewer/60113)
3.2. Objectif stratégique 3-2 – Évolution de la part de la population exposée à la sécheresse
3.2.1. Introduction
L’indicateur de l’objectif stratégique 3-2 définit l’exposition de la population au risque de sécheresse (identifié par l’indicateur de l’objectif stratégique 3-1) comme le nombre total de personnes exposées ainsi que comme le pourcentage de la population totale exposé. Cet indicateur peut ensuite être ventilé par sexe si des données sont disponibles en la matière.
La méthode de calcul s’appuie sur la répartition spatiale de la population ou du sous-groupe de population (c’est-à-dire les hommes, les femmes, etc.) pour établir son exposition à la sécheresse, en fonction du lieu et de l’étendue des catégories d’intensité de sécheresse, comme déterminé par l’indicateur de l’objectif stratégique 3-1. Grâce à ces informations, on peut calculer et communiquer le pourcentage de la population totale relevant de chaque catégorie d’intensité de sécheresse, ainsi que le pourcentage de la population totale exposé à la sécheresse (c’est-à-dire à toutes les catégories d’intensité de sécheresse). Les rapports nationaux sont facilités par la fourniture de données par défaut.
3.2.2. Conditions préalables à la présentation de rapports
Une lecture approfondie du chapitre 2 du Good Practice Guidance for National Reporting on UNCCD Strategic Objective 3: To mitigate, adapt to, and manage the effects of drought in order to enhance resilience of vulnerable populations and ecosystems, qui détaille la méthodologie employée pour estimer l’exposition à la sécheresse ;
Données conformes aux spécifications énumérées à la figure 6 et au tableau 20.
Une réserve de spécialistes nationaux officiellement nommés par les autorités nationales pour vérifier la cohérence des résultats du cycle de présentation des rapports au regard de la situation sur le terrain, ou pour élaborer et mettre en œuvre une méthodologie personnalisée pour estimer l’indicateur de l’objectif stratégique 3-2 si les données nationales sont privilégiées par rapport aux données par défaut. En l’occurrence, le bureau national de la statistique constitue la principale institution, mais les universités et les centres de recherche peuvent également apporter des contributions utiles.
3.2.3. Cycle de présentation des rapports et procédure étape par étape
La procédure étape par étape de présentation des rapports est décrite ci-après. Si l’on utilise les données par défaut, les étapes 2 à 4 ne sont pas nécessaires.
Étape 1 : sélectionner l’ensemble de données sur la population
Il existe plusieurs ensembles de données démographiques à résolution spatiale fine disponibles à l’échelle mondiale et l’un d’entre eux, WorldPop, est fourni par défaut aux pays parties pour calculer l’indicateur SO3-2. Les estimations nationales de la population féminine, masculine et totale pour la période 2000-2023 sont automatiquement pré-remplies dans le tableau CP-1.T2 et sont également disponibles sous forme de cartes annuelles quadrillées de la population. Toutefois, les parties doivent noter que l’ensemble de données WorldPop 2000-2020 utilisé comme source de données par défaut pour le rapport 2026 n’a pas été mis à jour et que, par conséquent, les trois dernières années (2021, 2022 et 2023) reproduisent les valeurs de 2020. Ces données peuvent être utilisées en l’absence de données démographiques nationales pour le calcul de l’indicateur SO3-2.
Cependant, les parties peuvent choisir d’utiliser d’autres ensembles de données mondiales ou nationales de comptages annuels de population ventilés par sexe. Dans ce cas, ces valeurs doivent être introduites dans CP1.T2. Les données sous-jacentes doivent être un produit de population quadrillé couvrant toute l’étendue du pays. Si l’ensemble de données disponible est un produit vectoriel (par exemple, représentant des zones administratives), il doit d’abord être converti en une grille régulière représentant le nombre de personnes vivant à chaque endroit (cellule de la grille). Idéalement, les données devraient être des comptages annuels de la population, pour le total ainsi que pour les groupes désagrégés par sexe (hommes, femmes).
Les parties qui souhaitent utiliser des ensembles de données démographiques nationales ou régionales peuvent utiliser l’arbre de décision de la figure 6 pour évaluer si ces données sont plus appropriées pour dériver l’indicateur SO 3-2 que les ensembles de données disponibles au niveau mondial.
Figure 6.** Arbre de décision pour aider les Parties à choisir la meilleure source de données démographiques pour dériver l’indicateur SO 3-2_.
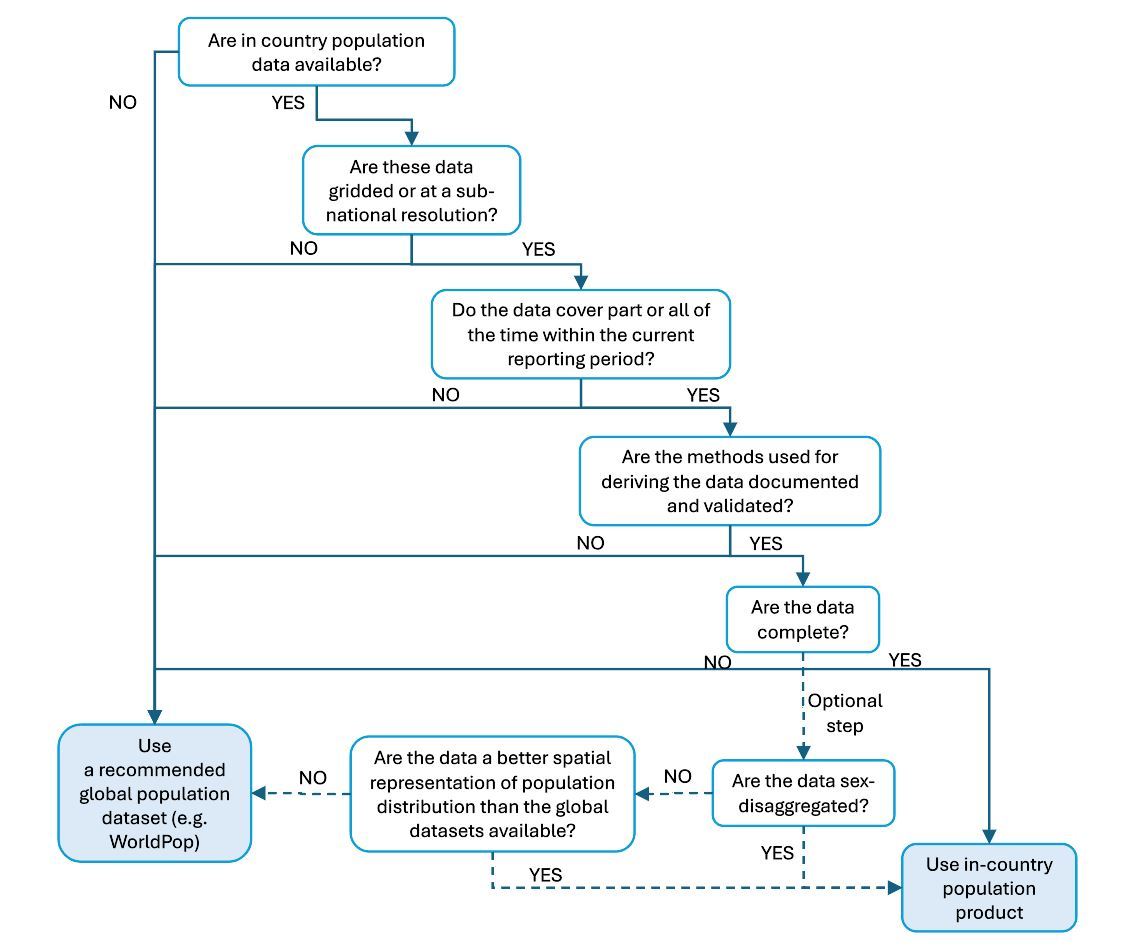
Ce processus de prise de décision devrait aider les Parties à identifier les données qui répondent aux spécifications résumées dans le tableau 20.
Élément |
Spécifications |
|
|---|---|---|
Données par défaut |
Données nationales |
|
Données d’entrée Données nécessaires pour générer l’indicateur SO 3-2, comme décrit dans les étapes 2 à 4 |
Données WorldPop pour chaque année de la période 2020-2023, ventilées par sexe (les données de 2020 étant dupliquées pour 2021, 2022 et 2023 en raison de l’absence de données actualisées de WorldPop sur la population après 2020). Données relatives aux catégories d’intensité de sécheresse, comme déterminé par l’indicateur de l’objectif stratégique 3-1. |
Produits maillés sur la population tirés des statistiques nationales officielles allant de l’année 2000 à l’année considérée, idéalement annuels et, si possible, ventilés par sexe. Données relatives aux catégories d’intensité de sécheresse, comme déterminé par l’indicateur de l’objectif stratégique 3-1. |
Données de sortie Produits maillés résultant de l’analyse décrite aux étapes 2 à 4 |
Produits quadrillés annuels de (i) la population totale, (ii) la population féminine et (iii) la population masculine exposées aux quatre classes d’intensité de la sécheresse de l’année 2015 à l’année de référence. Pourcentage de la population totale, féminine et masculine exposée à la sécheresse et à chaque classe d’intensité de la sécheresse. Résumé spatial en grille par périodes de quatre ans. |
Produit quadrillé annuel de (i) la population totale, (ii) la population féminine et (iii) la population masculine exposées aux quatre classes d’intensité de la sécheresse de l’année 2000 à l’année de référence. Pourcentage de la population totale, féminine et masculine exposée à la sécheresse et à chaque classe d’intensité de la sécheresse. Résumé spatial en grille par périodes de quatre ans. |
Résolution spatiale |
Données WorldPop : 3 secondes d’arc (~0,00083º ou ~100 m) Données sur l’intensité du risque de sécheresse : 0,1° x 0,1° (~11,1 km) |
Évaluée par les autorités nationales en fonction des données disponibles. |
Métadonnées |
Des métadonnées sont fournies avec les données par défaut. |
Les métadonnées minimales exigées pour chaque champ obligatoire sont énumérées à l’annexe II. |
Étape 2 : Superposition des données démographiques maillées avec les données spatiales de l’indicateur SO 3-1
L’indicateur SO 3-2 est calculé en superposant les données démographiques aux données spatiales sur l’intensité du risque de sécheresse (SO3-1) pour chaque année. Si des données autres que celles par défaut sont utilisées, les années manquantes doivent être complétées par les données démographiques disponibles les plus proches. Par exemple, si les données de 2019 sont manquantes, elles doivent être remplacées par les données de 2020 (ou l’année disponible la plus proche), puis les données de 2020 seront utilisées pour 2019 et 2020. Outre la population totale, les grilles de données démographiques ventilées par sexe, si elles sont disponibles, doivent être utilisées dans le processus de superposition pour générer des valeurs d’exposition à la sécheresse ventilées par sexe.
Les données relatives à la population et à l’intensité des risques de sécheresse doivent avoir le même système de référence de coordonnées et la même projection géographique, qui doivent être cohérents entre les périodes de déclaration annuelles. En outre, les deux ensembles de données doivent avoir la même taille de grille. Pour ce faire, les données GMID de 0,1° x 0,1° (~11,1 km) doivent être rééchantillonnées sur une grille de 0,00083º ( ~100 m) (identique à WorldPop) en utilisant la technique de rééchantillonnage du plus proche voisin.
Étape 3 : Calculer la proportion de la population exposée dans chaque classe d’intensité de la sécheresse
Note
Domaines connexes sur la plateforme du système PRAIS 4 : tableaux SO3-2.T1, SO3-2.T2 et SO3-2.T3
En utilisant les résultats de l’étape 2, le nombre de personnes appartenant à chacune des quatre classes d’intensité de la sécheresse, ainsi que le nombre total de personnes exposées à la sécheresse (c’est-à-dire à toutes les classes d’intensité de la sécheresse), peuvent être estimés pour chaque année. Les pourcentages respectifs sont ensuite calculés à partir de la population totale, comme indiqué dans CP-1.T2. Ces valeurs annuelles en pourcentage sont ensuite reportées dans le tableau SO3-2.T1. Le nombre total de la population exposée est calculé automatiquement par PRAIS à l’aide de la valeur de la population totale indiquée dans CP-1.T2. Ce chiffre est ensuite automatiquement reporté dans le tableau SO3-2.T1.
De même, si des données ventilées par sexe sont utilisées, pour chaque année disponible, le nombre d’hommes et de femmes dans chaque classe d’intensité de la sécheresse, ainsi que le nombre total d’hommes et de femmes exposés à la sécheresse, peuvent également être calculés. Ces chiffres doivent ensuite être exprimés en pourcentage par rapport à la population nationale totale de ce sexe. Les valeurs en pourcentage pour la population féminine sont indiquées dans le tableau SO3-2.T2. Les valeurs en pourcentage pour les hommes sont indiquées dans le tableau SO3-2.T3.
Les parties sont encouragées à soumettre, dans le champ Commentaires associé aux tableaux SO3-2.T1, SO3-2.T2 et SO3-2.T3, des commentaires sur la méthodologie, les sources de données et l’exactitude des données dans le cas où les estimations sont dérivées de données mondiales ou nationales alternatives qui ne sont pas des données par défaut.
Étape 4 : Créer des cartes d’exposition à la sécheresse par périodes de quatre ans
En plus des valeurs annuelles de l’indicateur SO 3-2 saisies dans les tableaux de l’étape 3, des cartes d’exposition à la sécheresse par périodes de quatre ans pour l’ensemble de la période doivent également être produites en externe et téléchargées dans PRAIS. Ces cartes d’exposition donnent une indication du nombre de personnes exposées à la classe de sécheresse la plus intense sur chaque période de quatre ans pour chaque cellule de la grille. Les périodes de quatre ans ont été choisies pour réduire la charge de travail et la quantité de données à télécharger dans PRAIS. Voir l’étape 5 de l’indicateur SO 3-1 pour plus de détails sur la préparation des cartes de sécheresse.
Étape 5 : Vérifier les résultats
Les parties doivent être conscientes des limites de l’utilisation de l’IPS comme indicateur de sécheresse (voir SO3-1 ci-dessus) et examiner d’un œil critique les résultats avant de soumettre les rapports à la CCD.
Étape 6 : Sauvegarder le formulaire et le mettre à disposition pour examen
Les changements observés et leur interprétation peuvent être décrits dans les champs de commentaires associés à chaque tableau de la plateforme PRAIS 4.
Les cartes par défaut sont disponibles dans la plateforme PRAIS 4 comme suit :
Population totale exposée à la sécheresse en 2000-2003
Population totale exposée à la sécheresse en 2004-2007
Population totale exposée à la sécheresse en 2008-2011
Population totale exposée à la sécheresse en 2012-2015
Population totale exposée à la sécheresse en 2016-2019
Population totale exposée à la sécheresse en 2020-2023
Ces cartes montrent la classe d’intensité de sécheresse la plus élevée à laquelle une population a été exposée au cours de chaque période de 4 ans, comme expliqué à l’étape 4.
Les parties qui génèrent des cartes dans Trends.Earth en utilisant des données nationales ou alternatives représentant la population exposée à la sécheresse peuvent télécharger les mêmes cartes listées ci-dessus dans PRAIS 4 s’ils disposent de suffisamment de données.
Les parties sont également encouragées à soumettre des commentaires sur la méthodologie, les sources de données et l’exactitude des données dans le cas où les estimations sont dérivées de données nationales en utilisant le champ “Commentaires généraux”. Il serait également utile de rendre compte des cas particuliers et des questions, en décrivant les situations dans lesquelles les valeurs pourraient être moins fiables et en justifiant l’adoption d’une méthodologie différente.
Une fois que le formulaire a été complété et vérifié par les Parties, il doit être marqué comme “En cours de révision” et sauvegardé. Une fois que l’UNCCD a terminé son examen et que tous les commentaires ont été résolus, le formulaire peut être marqué comme “Finalisé” et sauvegardé.
3.2.4. Dépendances
Les données sur l’exposition à la sécheresse reposent sur les sorties spatiales de l’OS 3-1 et les estimations de population du tableau CP-1.T2.
3.2.5. Difficultés
Disponibilité et qualité des données
Parmi les ensembles de données démographiques mondiales accessibles au public, l’ensemble de données WorldPop est utilisé par défaut par la CNULCD pour le calcul de l’indicateur SO2-3 et fourni aux Parties dans Trends.Earth. Il convient de noter que si l’École de géographie et des sciences de l’environnement de l’Université de Southampton (Royaume-Uni) a récemment publié un nouvel ensemble de données démographiques mondiales pour 2015-2030, il a été publié après le lancement du processus d’établissement des rapports 2026, et n’a donc pas pu être intégré dans les ensembles de données par défaut fournis aux Parties. Néanmoins, les Parties peuvent télécharger les nouveaux ensembles de données ventilées par sexe directement à partir d’ici : https://hub.worldpop.org/project/categories?id=8. Une [application GEE tierce] (https://sat-io.earthengine.app/view/worldpop) permet une exploration complète de l’ensemble de données. Si ces ensembles de données sont jugés appropriés, les Parties peuvent les télécharger sur Trends.Earth, calculer les données des indicateurs respectifs et importer les résultats dans PRAIS 4 pour remplacer les données par défaut.
Les parties doivent également noter que l’ensemble de données WorldPop 2000-2020 utilisé comme source de données par défaut pour le rapport 2026 n’a pas été mis à jour et que, par conséquent, les trois dernières années (2021, 2022 et 2023) reproduisent les valeurs de 2020.
La qualité des données mondiales et la résolution spatiale pourraient ne pas être suffisamment précises pour les estimations nationales de la population. L’intégration des données mondiales et nationales pourrait améliorer la qualité et la précision des résultats, mais nécessitera que les parties disposent de capacités de traitement et de compétences techniques supplémentaires.
La méthodologie ne tient compte que de la densité et de la répartition de la population, et ne couvre pas l’exposition des écosystèmes à la sécheresse. Une mesure de l’exposition à la sécheresse plus complète pourrait prendre en compte d’autres entités physiques à risque, telles que les rendements agricoles, les têtes de bétail, l’eau et certains types de végétation. Par ailleurs, le fait d’être exposé à la sécheresse n’est pas synonyme de vulnérabilité à la sécheresse.
3.2.6. Résumé (principales étapes)
Les principales étapes à suivre pour présenter des rapports sur l’exposition de la population au risque de sécheresse sont les suivantes :
Sélectionnez l’ensemble de données sur la population : Les parties peuvent décider d’utiliser les données par défaut ou d’autres sources mondiales ou nationales, à condition qu’elles soient conformes aux spécifications des données énumérées dans le tableau 20. Si les parties décident d’utiliser d’autres sources de données, elles doivent suivre les actions 2 à 4 ci-dessous.
Superposer les données sur la population au produit spatial de l’indicateur de l’objectif stratégique 3-1 : l’indicateur de l’objectif stratégique 3-2 est calculé en superposant les données annuelles sur la population aux données annuelles sur l’intensité du risque tirées de l’analyse de l’objectif stratégique 3-1.
Calculez la proportion totale exposée de la population ainsi que la proportion de la population dans chaque classe d’intensité de la sécheresse : la population totale exposée à la sécheresse, en termes de nombre de personnes, est auto-calculée dans PRAIS 4 sur la base des données démographiques rapportées dans CP-1.T2. La proportion d’hommes et de femmes dans chaque classe d’intensité de la sécheresse doit également être indiquée.
Créer des cartes d’exposition à la sécheresse par périodes de quatre ans : le résumé spatial maillé pour chaque période de quatre ans fournit des informations sur le nombre de personnes exposées à la classe d’intensité de sécheresse la plus élevée sur chaque période de quatre ans, de 2000 (ou l’année la plus ancienne pour laquelle des données démographiques sont disponibles) à l’année de référence, à l’échelle de la cellule de la grille. Ces périodes de quatre ans doivent être cohérentes avec les résumés spatiaux maillés rapportés dans l’OS 3-1.
Vérifier les résultats : conscientes des limites des valeurs estimées de l’exposition à la sécheresse, les Parties peuvent vérifier l’exactitude et la fiabilité de cet indicateur dans leur pays avant de soumettre officiellement leurs estimations aux fins des rapports au titre de la CNULCD.
Sauvegarder le formulaire et le rendre disponible pour examen : une fois vérifiés par les parties, les données et le texte justificatif doivent être marqués comme “en cours d’examen” et sauvegardés, ce qui les rend disponibles pour examen par la CNULD.
3.2.7. Ressources supplémentaires
Beta Test de nos nouvelles données sur la population mondiale - 2015 à 2030, WorldPop (https://www.worldpop.org/blog/beta-test-our-new-global-population-data-2015-to-2030/)
3.3. Objectif stratégique 3-3 – Évolution du degré de vulnérabilité à la sécheresse
3.3.1. Introduction
L’approche adoptée par la CNULCD pour évaluer la vulnérabilité à la sécheresse s’appuie sur un indice composite, l’indice de vulnérabilité à la sécheresse, qui intègre trois composantes représentant la vulnérabilité de la population d’un pays individuel à la sécheresse : i) sociale, ii) économique et iii) infrastructurelle. À l’heure actuelle, cet indice ne tient pas compte de la vulnérabilité écologique ou écosystémique.
On peut calculer l’indice de vulnérabilité à la sécheresse au moyen de trois processus différents, correspondant à trois niveaux croissants de complexité :
Évaluation de la vulnérabilité de niveau 1 : utilise au moins un facteur par composante de la vulnérabilité, représenté par des mesures à l’échelle du pays.
Évaluation de la vulnérabilité de niveau 2 : utilise plus d’un facteur par composante de la vulnérabilité, les facteurs étant représentés par des mesures à l’échelle du pays, en incluant des données ventilées par sexe (le cas échéant).
AV de niveau 3 - utilise plus d’un facteur par composante de vulnérabilité, où les facteurs sont représentés par des métriques infranationales (qui peuvent être réparties en grille ou désagrégées par régions administratives), avec l’inclusion de données ventilées par sexe (le cas échéant).
Les Parties peuvent choisir l’approche la mieux adaptée à leurs capacités actuelles en matière de collecte et de traitement de données, en fonction de la disponibilité des données.
La CNULCD fournit aux Parties des données par défaut tirées de l’ensemble de données mondial sur l’indice de vulnérabilité à la sécheresse du Centre commun de recherche de la Commission européenne pour faciliter la présentation des rapports. Ces données sont tirées d’ensembles de données disponibles au niveau mondial et doivent être utilisées en l’absence de données plus précises au niveau national.
3.3.2. Conditions préalables à la présentation de rapports
Une lecture approfondie du chapitre 3 du Good Practice Guidance for National Reporting on UNCCD Strategic Objective 3: To mitigate, adapt to, and manage the effects of drought in order to enhance resilience of vulnerable populations and ecosystems, qui détaille la méthodologie employée pour estimer la vulnérabilité à la sécheresse ;
Des données conformes aux spécifications énumérées dans le tableau 21 ;
Une réserve de spécialistes nationaux officiellement nommés par les autorités nationales pour vérifier la cohérence des résultats du cycle de présentation des rapports au regard de la situation sur le terrain, ou pour élaborer et mettre en œuvre une méthodologie personnalisée pour estimer l’indicateur de l’objectif stratégique 3-3 si les données nationales sont privilégiées par rapport aux données par défaut. En l’occurrence, le bureau national de la statistique constitue la principale institution, mais les universités et les centres de recherche peuvent également apporter des contributions utiles.
3.3.3. Cycle de présentation des rapports et procédure étape par étape
La procédure de déclaration étape par étape est décrite ci-après. Si les données par défaut sont utilisées, les étapes 2 à 5 sont inutiles.
Étape 1 : sélectionner le niveau de l’évaluation de la vulnérabilité en fonction de la disponibilité des données
Les facteurs de vulnérabilité (énumérés dans la figure 7) recommandés par la CCD pour calculer l’IVC donnent un aperçu de la vulnérabilité socio-économique d’une partie à la sécheresse. Les trois facteurs fondamentaux recommandés pour l’AV minimale de niveau 1 sont les suivants :
Taux d’alphabétisation (% des personnes âgées de 15 ans et plus) ;
Proportion de la population en dessous du seuil international de pauvreté
Proportion de la population utilisant des services d’eau potable gérés en toute sécurité.
Ils ont été sélectionnés parce qu’ils ont été identifiés par des experts comme étant essentiels à la compréhension de la vulnérabilité et parce qu’ils sont utilisés pour d’autres exigences en matière de rapports, telles que l’OS 2 et les objectifs de développement durable.
Figure 7.** Composantes sociales, économiques et infrastructurelles et leurs facteurs associés recommandés pour le calcul de l’indice de vulnérabilité à la sécheresse. Les facteurs essentiels sont mis en évidence dans les cases vertes foncées.
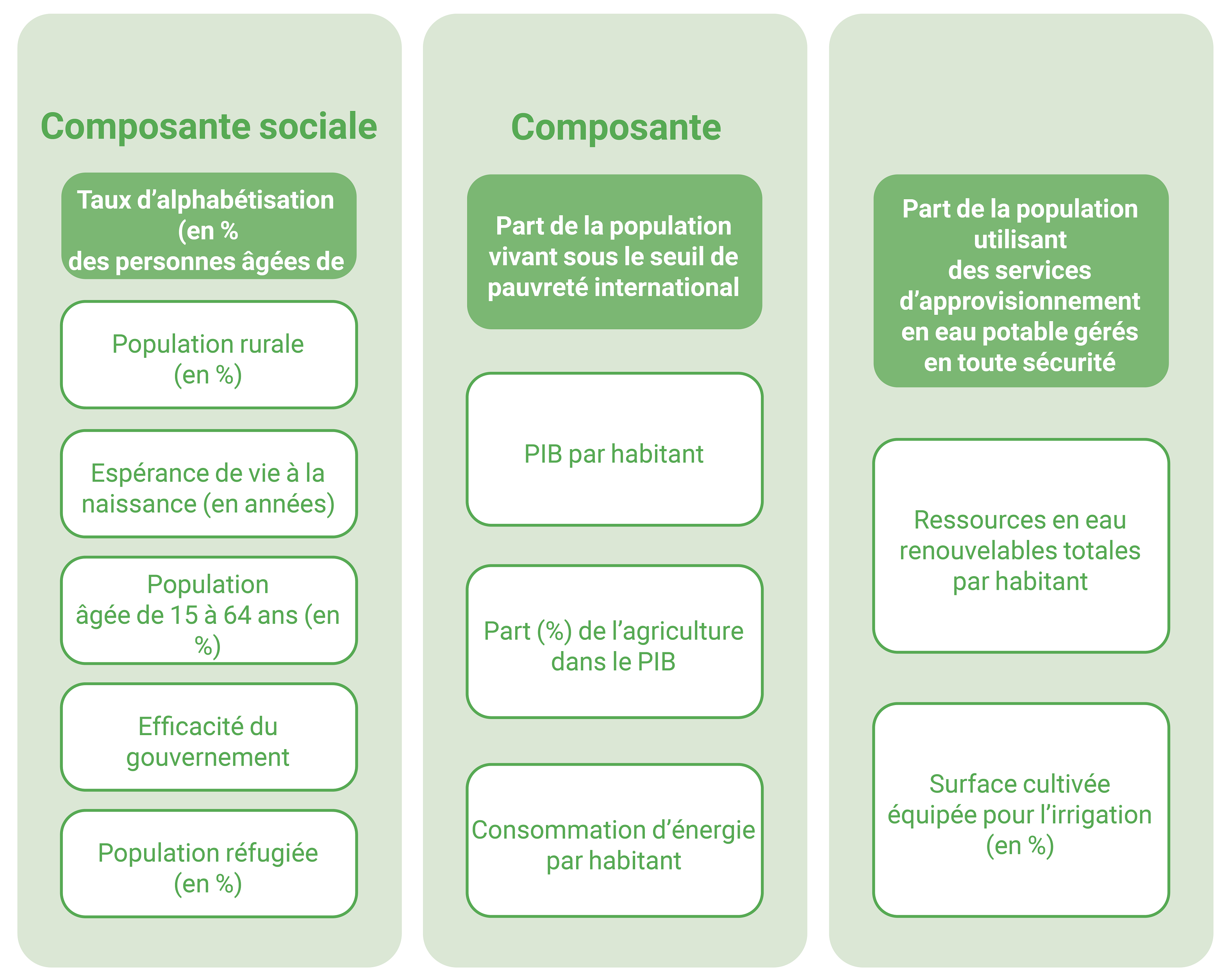
La CCD fournit des données par défaut à partir de l’ensemble de données mondiales d’IVC du CCR. La méthode utilisée pour dériver l’IVC par défaut est similaire à celle présentée dans ce manuel et dans le [“Guide des bonnes pratiques pour l’établissement des rapports nationaux sur l’objectif stratégique 3 de la CNULCD”] (https://www.unccd.int/sites/default/files/documents/2021-09/UNCCD_GPG_Strategic-Objective-3_2021.pdf), mais présente quelques différences majeures en termes de méthode de normalisation (voir l’étape 2) et de nombre de facteurs inclus. Deux facteurs supplémentaires sont utilisés dans l’IVC par défaut : « Prévention et préparation aux catastrophes (USD/an/capital) « et « Carte mondiale de l’accessibilité : Temps de trajet vers les grandes villes ». Une seule valeur d’IVC par défaut est fournie et représente l’IVC médian dans l’ensemble du pays pour la période 2000-2018. Par conséquent, cette valeur par défaut est utilisée pour renseigner l’année 2018 dans le tableau SO3-3.T1.
Les pays parties qui ne disposent pas des données nécessaires pour calculer la VA minimale de niveau 1 peuvent utiliser les données par défaut de l’IVC. Toutefois, il est recommandé de s’efforcer, au cours des cycles de déclaration successifs, de passer aux niveaux supérieurs de la VA afin d’accroître la sensibilité de l’IVC et d’améliorer la granularité de l’évaluation. L’arbre de décision de la figure 8 aide les parties à sélectionner le niveau d’AV en fonction de la disponibilité des données.
Les données nationales ou régionales utilisées pour calculer l’indice de vulnérabilité à la sécheresse doivent être conformes aux spécifications énumérées dans le tableau 21.
Figure 8.** Arbre de décision pour aider les Parties à choisir le meilleur niveau d’évaluation de la vulnérabilité pour le rapport sur l’indicateur SO 3-3 en fonction de la disponibilité des données.
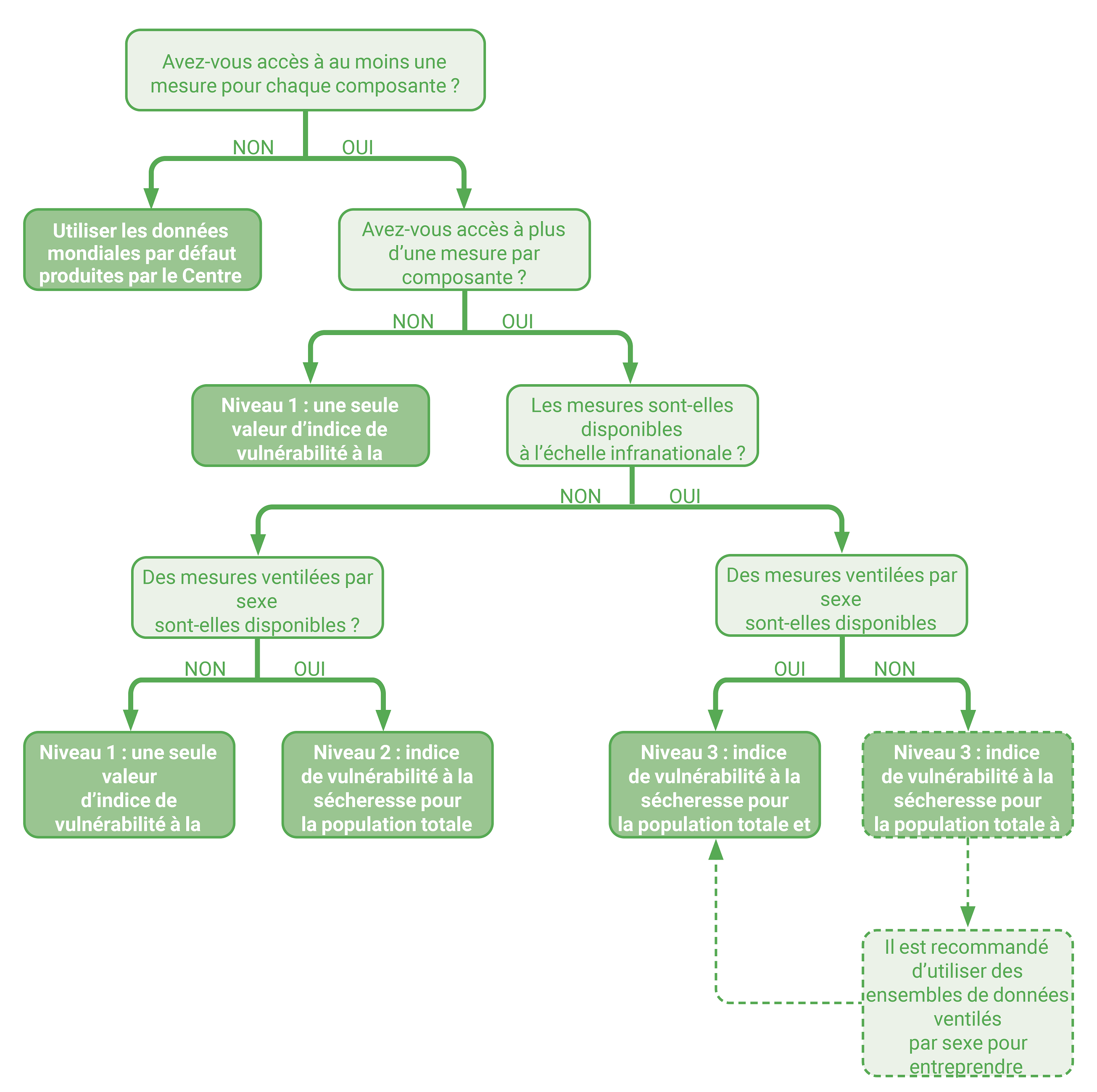
DVI : Indice de vulnérabilité à la sécheresse
VA : Évaluation de la vulnérabilité
Élément |
Spécifications |
|
|---|---|---|
Données par défaut (ensemble de données sur l’indice de vulnérabilité à la sécheresse produit par le Centre commun de recherche) |
Données nationales |
|
Données d’entrée Données nécessaires pour générer l’indicateur SO 3-3 tel que décrit dans les étapes 2 à 4 |
Les données utilisées pour calculer l’indice de vulnérabilité à la sécheresse (IVS) par défaut proviennent de diverses sources telles que la Banque mondiale, l’Organisation de coopération et de développement économiques, l’Organisation des Nations unies pour l’alimentation et l’agriculture et le Centre commun de recherche de la Commission européenne. |
Des ensembles de données disponibles en accès libre pour calculer les facteurs nécessaires à la détermination de l’indice de vulnérabilité à la sécheresse sont énumérés dans le tableau 14 du Good Practice Guidance for National Reporting on UNCCD Strategic Objective 3. Alternativement, s’ils sont disponibles, des ensembles de données nationales avec une résolution spatiale plus élevée et moins de lacunes pour la période 2000-2023. |
Données de sortie Indicateur d’IVC résultant de l’analyse décrite aux étapes 2 à 4 |
2018 DVI |
IVC annuelle ou quasi annuelle pour la période 2000-2023. |
Classification |
Échelle fractionnelle continue de 0 à 1 mais classification fondée sur des quintiles pour regrouper les catégories de vulnérabilité. |
Échelle continue de 0 à 1. |
Résolution spatiale |
Niveau national |
Niveaux national et/ou infranational |
Qualité |
Spécifié dans les métadonnées de l’ensemble de données. |
À indiquer dans les métadonnées de l’ensemble de données. |
Métadonnées |
Des métadonnées sont fournies avec les données par défaut. |
Les métadonnées minimales exigées pour chaque champ obligatoire sont énumérées à l’annexe II. |
Étape 2 : normalisation des facteurs
À tous les niveaux de l’évaluation de la vulnérabilité, les facteurs de vulnérabilité doivent être normalisés avant de pouvoir les comparer et les agréger, car ils sont tous mesurés à l’aide d’unités différentes.
Le [Guide des bonnes pratiques pour les rapports nationaux sur l’objectif stratégique 3 de la CCD] (https://www.unccd.int/sites/default/files/documents/2021-09/UNCCD_GPG_Strategic-Objective-3_2021.pdf) recommande de normaliser les facteurs en utilisant les valeurs maximales et minimales au sein du pays en utilisant toutes les données historiques jusqu’à et y compris la dernière année pour le rapport (2023). Cela permet d’obtenir la fourchette la plus large possible, en garantissant que les valeurs maximales et minimales sont représentatives du pays.
En cas de corrélation/relation positive entre la vulnérabilité et le facteur[3] (autrement dit, si la valeur du facteur augmente, la vulnérabilité augmente également), les données doivent être normalisées au moyen de l’équation ci-dessous :
\(Factor = \frac{X_{i} - X_{min}}{X_{max} - X_{min}}\)
Où :
Xi est la valeur du facteur considéré pendant l’année « i » ;
Xmin est la valeur minimale du facteur considéré observée sur la totalité de la série chronologique ;
Xmax est la valeur maximale du facteur considéré observée sur la totalité de la série chronologique.
En cas de corrélation/relation négative entre la vulnérabilité et le facteur, l’équation est la suivante :
\(Factor = 1 - \frac{X_{i} - X_{min}}{X_{max} - X_{min}}\)
Après la normalisation, tous les facteurs affichent une valeur située entre zéro et un, relative aux valeurs maximale et minimale historiques du pays en question.
La normalisation des données ventilées par sexe pour les VA de niveau 1 et 2 utilise les mêmes formules que celles décrites ci-dessus, appliquées une fois pour chaque donnée ventilée par sexe.
Concernant les données au niveau infranational (évaluation de niveau 3), le calcul doit être appliqué aux données tirées de toutes les unités spatiales (par exemple, les unités administratives) combinées, et la fourchette des facteurs doit refléter les valeurs minimale et maximale du pays tout entier.
Concernant l’indice de vulnérabilité à la sécheresse par défaut, chaque facteur a été normalisé au moyen des valeurs maximale et minimale mondiales, au lieu des fourchettes historiques pour le pays en question. La normalisation à l’échelle mondiale signifie que l’évaluation de la vulnérabilité qui en résulte est moins sensible à la situation locale/nationale que si l’on avait utilisé une fourchette nationale.
Étape 3 : calculer les composantes de l’indice de vulnérabilité à la sécheresse
Cette étape vise à obtenir des valeurs agrégées pour chacune des trois composantes de l’IVC. Pour les Parties qui n’utilisent qu’un seul facteur par composante de vulnérabilité, les valeurs du facteur normalisé à l’étape 2 sont également représentatives de la composante correspondante. En revanche, l’utilisation de plus d’un facteur par composante de vulnérabilité nécessite le calcul de la moyenne arithmétique des facteurs normalisés pour obtenir la valeur agrégée de chaque composante.
Le résultat de cette étape est une valeur unique pour chaque composante et chaque unité géographique du pays. Si des données ventilées par sexe sont utilisées, des valeurs distinctes pour les populations masculine et féminine sont produites pour chaque composante.
Les parties peuvent attribuer des pondérations aux facteurs de vulnérabilité si leur importance relative et leur pertinence sont connues. Il est recommandé d’appliquer les pondérations à chaque facteur de vulnérabilité et non aux trois composantes.
Étape 4 : calculer l’indice de vulnérabilité à la sécheresse (IVS)
Note
Domaines connexes sur la plateforme du système PRAIS 4 : tableau SO3-3.T1
À tous les niveaux de l’évaluation de la vulnérabilité, les trois composantes (Csociale, Céconomique et Cinfrastructurelle) calculées aux étapes précédentes servent à produire l’indice de vulnérabilité à la sécheresse en calculant leur valeur moyenne.
\(IVS = \frac{C_{\text{sociale}} + C_{\text{économique}} + C_{\text{infrastructurelle}}}{3}\)
L’indice de vulnérabilité à la sécheresse va de 0 à 1, 1 représentant la plus grande vulnérabilité.
Une VA de niveau 1 se traduirait par un IVC au niveau national pour chaque année pour laquelle des données sont disponibles (idéalement de 2000 à 2023). Pour les AV de niveaux 2 et 3, lorsque des facteurs ventilés par sexe sont utilisés, il est recommandé de calculer également des IVC spécifiques au sexe, en plus de l’IVC au niveau national. Par conséquent, une Partie déclarera trois valeurs d’IVC pour chaque année disponible, c’est-à-dire pour la population totale, la population féminine et la population masculine. Pour les composantes infranationales ou maillées relevant de la VA de niveau 3, l’IVC doit être calculé pour la plus petite unité spatiale, séparément pour les hommes, les femmes et les populations totales. Les valeurs annuelles de l’IVC pour les hommes, les femmes et la population totale doivent être utilisées pour compléter le tableau SO3-3.T1.
Étape 5 : Déclarer les facteurs utilisés pour calculer l’IVC
Lorsque des données nationales sont utilisées pour compléter le tableau SO3-3.T1, les Parties doivent également indiquer les facteurs utilisés dans le calcul. Une fois les données saisies dans le tableau SO3-3.T1, une série de tableaux supplémentaires sous le titre “Méthode” sera mise à disposition pour être complétée. Pour chacune des composantes sociales, économiques et structurelles, les Parties doivent identifier les facteurs utilisés dans le calcul de l’IVC. En outre, les Parties doivent indiquer, pour chaque facteur utilisé, si des données ventilées par sexe sont disponibles et si les calculs ont été effectués à un niveau infranational.
Une fois les tableaux complétés, PRAIS déterminera et affichera automatiquement le niveau utilisé dans l’évaluation.
Les parties doivent également indiquer comment l’IVC évolue dans le temps, en sélectionnant l’une des options du tableau SO3-3.T2. Des informations complémentaires peuvent être fournies dans le champ de commentaires associé.
Étape 6 : vérifier les résultats
La méthode d’IVC n’a pas encore été validée à l’échelle locale ou nationale et, en tant que telle, peut ne pas caractériser avec précision la vulnérabilité à ces échelles, que ce soit en termes de facteurs les plus pertinents pour chaque pays ou de schéma de pondération des facteurs le plus efficace. Par conséquent, les Parties peuvent vérifier l’adéquation des facteurs par défaut et ajouter des facteurs pertinents si nécessaire. Tout système de pondération utilisé par les parties devrait également faire l’objet d’une évaluation approfondie s’il est utilisé pour améliorer les résultats aux niveaux national et infranational.
En outre, les populations les plus vulnérables et les groupes sous-représentés doivent participer à la détermination des facteurs qui seront utilisés pour calculer les composantes, afin d’élaborer un indice spécifique au pays et plus efficace.
Étape 7 : Sauvegarder le formulaire et le mettre à disposition pour examen
Les informations sur la méthode utilisée (niveau sélectionné et facteurs par composant) doivent être rapportées en utilisant le champ de commentaires dédié associé au tableau SO3-3.T1 dans la plateforme PRAIS 4. Les changements observés et leur interprétation peuvent également être décrits dans ce champ.
Les cartes générées dans Trends.Earth à l’aide de données nationales dans le cadre de la VA de niveau 3 et représentant la vulnérabilité à la sécheresse au cours de la période analysée peuvent être téléchargées sur la plateforme PRAIS 4. Plus précisément, il est recommandé de télécharger les cartes suivantes :
Vulnérabilité à la sécheresse pour l’année 2000 ou l’année disponible la plus proche
Vulnérabilité à la sécheresse pour l’année 2023 ou l’année disponible la plus proche
Des informations sur les sources de données, l’exactitude des données et tout système de pondération appliqué aux facteurs de vulnérabilité peuvent être fournies dans le champ “Commentaires généraux”. Il serait également utile de signaler les cas particuliers et les problèmes, en décrivant les situations dans lesquelles les valeurs peuvent être moins fiables et en justifiant l’inclusion de différents facteurs.
Une fois que le formulaire a été complété et vérifié par les Parties, il doit être marqué comme “En cours de révision” et sauvegardé. Une fois que l’UNCCD a terminé son examen et que tous les commentaires ont été résolus, le formulaire peut être marqué comme “Finalisé” et sauvegardé.
3.3.4. Dépendances
Les OS 2-1 et OS 2-2 peuvent être utilisés pour le calcul de l’OS 3-3. Ceci est expliqué dans le [Guide des bonnes pratiques pour les rapports nationaux sur l’objectif stratégique 3 de la CNULD] (https://www.unccd.int/sites/default/files/documents/2021-09/UNCCD_GPG_Strategic-Objective-3_2021.pdf). Chapitre 3. Indicateur de niveau 3.
3.3.5. Difficultés
Disponibilité et qualité des données
L’ensemble des données mondiales d’IVC du CCR n’est disponible que pour l’année 2018.
La disponibilité de données relatives aux facteurs considérés varie grandement d’un pays à l’autre et l’on pourrait ne pas disposer partout de toutes les données recommandées.
Approche méthodologique
La fiabilité de la méthode d’IVC aux niveaux national et infranational doit encore être vérifiée par des experts nationaux.
En raison des méthodes employées pour normaliser les facteurs (à savoir utiliser les données historiques nationales), les valeurs de l’indice de vulnérabilité à la sécheresse ne doivent pas être comparées entre les pays.
Si l’on part du principe qu’une méthodologie constante a été appliquée au fil du temps, les variations de l’indice de vulnérabilité à la sécheresse pourraient refléter l’efficacité des politiques d’atténuation des effets de la sécheresse et d’adaptation à ceux-ci, mais elles pourraient également révéler les impacts de changements sociaux et économiques déconnectés des mesures de gestion de la sécheresse.
3.3.6. Résumé (principales étapes)
Les principales étapes à suivre pour présenter des rapports sur la vulnérabilité de la population au risque de sécheresse sont les suivantes :
Choisissez le niveau d’évaluation de la vulnérabilité en fonction de la disponibilité des données : Les parties sont encouragées à opter pour l’un des trois niveaux d’évaluation de la vulnérabilité en fonction de la disponibilité des données. En l’absence de données permettant de calculer la VA minimale de niveau 1, les parties peuvent utiliser les données par défaut. Les produits de données nationales/régionales utilisés pour calculer l’IVC doivent être conformes aux spécifications énumérées dans le tableau 21. Si les parties utilisent des produits de données nationaux/régionaux, elles doivent suivre les actions 2 à 4 ci-dessous :
Normalisation des facteurs : les facteurs de chaque composante de la vulnérabilité doivent être normalisés avant de pouvoir les comparer et les agréger, car ils sont tous mesurés à l’aide d’unités différentes.
Calculer les composantes de l’indice de vulnérabilité à la sécheresse : les valeurs cumulées des trois composantes de l’indice de vulnérabilité à la sécheresse sont calculées sous la forme de la moyenne arithmétique des facteurs normalisés.
Calcul de l’IVC : les trois composantes - sociale, économique et infrastructurelle - dérivées des étapes précédentes sont utilisées pour produire les valeurs annuelles de l’IVC en calculant leur valeur moyenne arithmétique.
Déclarer les facteurs utilisés pour calculer l’IVC : Lorsque des données nationales sont utilisées pour compléter le tableau SO3-3.T1, les Parties doivent également indiquer les facteurs utilisés pour le calcul.
Vérifier les résultats : conscientes du fait que la méthode d’IVC n’a pas encore été validée à l’échelle locale ou nationale, les parties doivent vérifier l’adéquation des facteurs par défaut et ajouter des facteurs pertinents si nécessaire avant de soumettre officiellement des estimations pour les rapports de la CNULD.
Sauvegarder le formulaire et le rendre disponible pour examen : une fois vérifiées par les parties, les données et le texte justificatif pour la période évaluée doivent être marqués comme “en cours d’examen” et sauvegardés, ce qui les rend disponibles pour examen par la CNULD.